
Unlocking the Power of LLMs: RAG and Fine-Tuning Techniques
Written by Angelo Consorte | Published on November 24, 2024
Retrieval-Augmented Generation (RAG) and Fine Tuning are two distinct techniques used in machine learning to enhance the performance of large language models (LLMs). Each of these techniques has its pros and cons and, in this text, we are going to discuss what exactly they are, how they can be useful, why we use them, and what cases to use them.

LLM Difficulties
The development of Large Language Models with user friendly interfaces is a movement that has changed the world. Available for everybody for free, LLMs like Chat GPT, Google Gemini, and Llama are incredible tools for innumerous tasks that help us by empowering individuals and businesses to achieve more with less effort. These tools provide unprecedented access to advanced AI capabilities, allowing users to draft essays, generate creative ideas, analyze data, translate languages, and even write code, all from a simple and intuitive interface. Their accessibility has democratized technology, breaking down barriers to entry for complex tasks that previously required specialized skills or resources.
Even considering all its capabilities, models have their limitations that can restrict how helpful they can be. One of their limitations is that sometimes, to answer questions accurately, LLMs have to be trained on that specific data. Imagine a scenario where someone asks the LLM:
“What are the opening hours of the new café, Sunshine Roastery, that opened in downtown Springfield last month?”
If the LLM was trained on a dataset that predates the café’s opening or lacks detailed information about small, local businesses, it might not have any data on the café.
LLMs rely on pre-existing datasets for their knowledge. Unless the model is updated or augmented with external web-based queries, it cannot provide accurate or current details about events or entities that appeared after its training period or fall outside the scope of its dataset.
Another limitation of LLMs is their inherently generalistic nature, which can make them less effective for highly specific or specialized tasks. While they excel at providing broad, context-aware responses, they often lack the precision or depth required for niche applications. For example, a business in the pharmaceutical industry might need detailed insights into drug interactions or compliance regulations specific to a particular country. An LLM trained in general knowledge might provide surface-level information or outdated guidelines, which could be insufficient or even misleading.
This is when techniques like Fine Tuning and Retrieval Augmented Generation come into play. On their particular ways, these techniques help us enhance the use of LLMs for our needs. In the next paragraphs we are going to define each technique and discuss what are the best uses for them.
Retrieval Augmented Generation (RAG)
What is RAG?
RAG, or Retrieval-Augmented Generation, is an architecture framework introduced by Meta in 2020 that combines a language model with an external retrieval mechanism.
Unlike traditional LLMs that rely exclusively on pre-trained knowledge, RAG dynamically pulls relevant information from a connected knowledge base, database, or document repository to generate responses. This means that the output is not just based on what the model has learned during training but is also influenced by the most pertinent data retrieved in real time. This makes RAG particularly powerful for applications requiring precise, contextually rich, and up-to-date answers.
How does our interactions with LLMs that use RAG work?
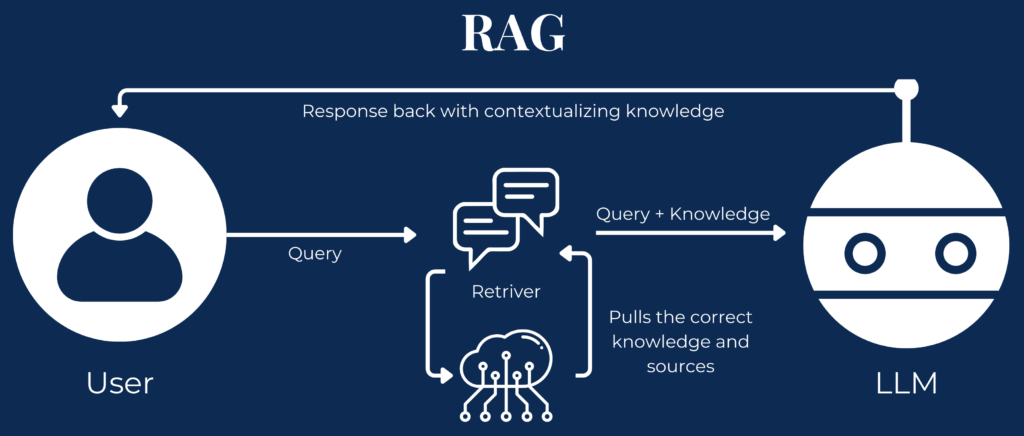
- Query processing: The process starts when a user inputs a query into the system, initiating the retrieval mechanism of the RAG chain.
- Data retrieval: The RAG system then searches the database for relevant information based on the query, utilizing advanced algorithms to match the query with the most suitable and contextually appropriate data.
- Integration with the LLM: The retrieved data is combined with the user’s original query and passed to the LLM.
- Response generation: Leveraging the LLM’s capabilities and the context from the retrieved data, the system produces a response that is accurate and tailored to the query’s specific context.
Pros of RAG
- Access to up-to-date information: RAG allows the model to retrieve real-time data, ensuring that responses are current and reflect the latest knowledge.
- Improved accuracy: By incorporating external, curated databases, RAG can provide more precise and reliable answers than a model relying solely on its internal training data.
- Increased flexibility: It can be applied to various domains, as it can pull information from different databases or sources tailored to the specific task.
- Cost-effective: RAG is cheaper than fine-tuning, as it does not require retraining the entire model and instead relies on retrieving external information to improve performance.
Cons of RAG
- Dependency on external data sources: RAG’s performance is tied to the quality and reliability of external databases or retrieval systems. If the sources are outdated, inaccurate, or incomplete, the generated responses may suffer.
- Increased computational overhead: Retrieving relevant information from external sources adds extra processing time and computational resources, which can affect response time and scalability.
Fine Tuning
What is Fine Tuning?
Fine-tuning, a technique in machine learning where a pre-trained model is further trained on a new, specific dataset, has been utilized since the early 1990s. This approach gained prominence with the advent of deep learning, particularly in natural language processing (NLP) and computer vision tasks.
Instead of training a model from scratch, fine-tuning leverages the existing knowledge embedded in a pre-trained model and refines it with additional data. This approach, which became widely adopted with the advent of models like BERT and GPT, allows developers to optimize a model’s performance for specific use cases while significantly reducing the time, computational resources, and data requirements compared to training from the ground up.
How does our interactions with LLMs that use Fine Tuning work?
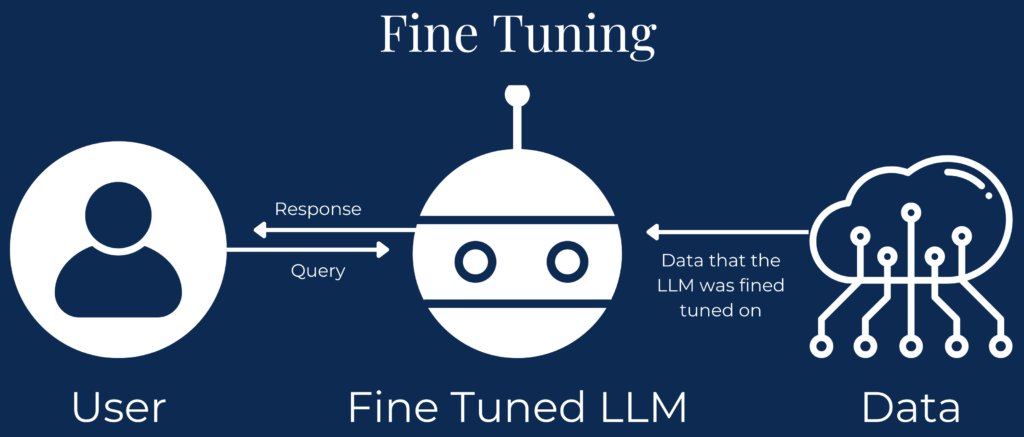
- Preprocessing: The interaction begins when a user submits an input. The input is then processed to ensure it aligns with the format and structure expected by the fine-tuned model, such as tokenization for text inputs or normalization for images.
- Inference with the fine-tuned model: The preprocessed input is passed to the fine-tuned model, which applies its domain-specific adjustments and learned patterns to generate a response or prediction.
- Postprocessing: The model’s output is refined, if necessary, to meet the user’s desired format or additional constraints, such as converting probabilities into a class label or generating user-friendly text.
Pros of Fine Tuning
- Faster Responses Compared to RAG: Fine-tuned models embed all relevant knowledge into their weights, eliminating the need for external retrieval processes, resulting in faster and more efficient response generation.
- Understanding of the Domain: Fine-tuning trains the model to grasp overarching domain concepts, enabling it to generalize across related tasks rather than relying solely on isolated dataset-specific knowledge.
- Style and Tone: Fine-tuning allows the model to be adapted to a specific tone, style, or level of formality, making it ideal for tailored communications, creative writing, or brand-aligned outputs.
- Offline Functionality: Fine-tuned models do not rely on external data sources or internet connectivity, making them more secure and practical for offline environments.
Cons of Fine Tuning
- Higher Costs Compared to RAG: Fine-tuning requires significant computational resources, time, and expertise, which can make it more expensive than RAG, especially for large-scale models.
- Challenging to Update Knowledge: Updating a fine-tuned model with new information requires retraining or re-fine-tuning, making it time-intensive and impractical for rapidly changing domains.
- Risk of Overfitting on Small or Specialized Datasets: Fine-tuning on limited or narrow datasets can lead to overfitting, where the model performs well on training data but poorly on new, unseen data.
- Limited Scalability Across Multiple Domains: Scaling fine-tuned models for diverse domains require separate fine-tuning for each, which can quickly become resource prohibitive.
Use Cases of RAG
Dynamic Databases
- RAG works well when you need to continuously pull information from dynamic, updated data sources like databases, APIs, or document repositories.
- Real-World Example: a helpdesk assistant fetching up-to-date FAQs, troubleshooting guides, or policy documents directly from a company’s knowledge base to answer customer queries. This ensures that the responses are current and relevant without requiring model retraining.
Systems that Require Sources:
- RAG supports the retrieval of external data with citations, making it easier to provide transparent and verifiable responses.
- Real-World Example: a Legal Research Tool that retrieves case law, statutes, or legal precedents along with their sources, providing lawyers with not just the information but its origin for further review.
Reducing Hallucinations
- By fetching information directly from reliable sources, RAG minimizes hallucinations, improving trust in its outputs.
- Real-World Example: a Medical Diagnosis Assistant for clinicians that retrieves recent studies, drug information, or treatment guidelines from medical databases like PubMed, ensuring that responses are based on verifiable sources.
Maintenance
- The external data source can be curated and updated without retraining the model. This makes it easier to manage evolving knowledge and ensure accuracy.
- Real-World Example: an E-Commerce Assistant chatbot that retrieves product availability, pricing, and reviews directly from a store’s inventory system, ensuring responses reflect the latest updates.
Use Cases of Fine Tuning
Influence on Model Behaviors and Reactions
- Fine-tuning allows precise control over the model’s behavior by training it on domain-specific data, aligning it closely with specific tasks, styles, or company branding.
- Real-World Example: a Customer Service Chatbot fine-tuned model for a financial institution that adheres to a formal tone, understands nuanced financial jargon, and provides tailored responses for banking products.
Speed, Inference Cost, and Offline Capabilities
- Once fine-tuned, the model is standalone and can operate offline, providing faster responses with lower inference costs compared to using a retrieval mechanism.
- Real-World Example: a fine-tuned model deployed on an offline device, like a virtual assistant in a smart home system, ensuring low latency and no dependency on internet connectivity.
Cultural Sensitivity and Emotional Intelligence
- Fine-tuning allows models to adapt their tone, language, and behavior to align with cultural norms and emotional needs, creating more personalized and respectful interactions.
- Real-World Example: a global chatbot that adjusts its tone to match cultural expectations (e.g., politeness in Japanese interactions) while also detecting user sentiment to provide empathetic and emotionally aware responses.
Combining Both Techniques
Finally, it is also possible to combine both techniques in order to build even more complex applications. By putting both tactics together, we can take advantage of the characteristics of both and provide better outputs for users.
- Personalized educational tutor: an application designed to assist students across various subjects and skill levels.
- RAG components: The application dynamically retrieves the latest curriculum updates, reference materials, or specific answers from trusted educational repositories like academic journals, textbooks, or online resources, ensuring that the information provided is accurate, up-to-date, and sourced.
- Fine-Tuning Component: The model is fine-tuned to understand the emotional and motivational needs of learners, adapting its tone and instructional style to the user’s preferences. For instance, it could provide encouraging feedback for a struggling student or challenge an advanced learner with more complex problems.
This dual approach creates a tutor that is not only reliable in its information but also engaging, empathetic, and effective in fostering personalized learning experiences.
Conclusion
In conclusion, Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful yet distinct approaches to optimizing Large Language Models (LLMs), each directed to specific uses and challenges. RAG is better in dynamic, real-time scenarios requiring access to up-to-date, contextual information, while Fine-Tuning excels in creating domain-specific, stylistically consistent, and offline-ready models.
Choosing between these techniques—or combining them—depends on your goals and constraints. RAG’s real-time retrieval capability ensures flexibility and accuracy for constantly evolving knowledge bases, on the other hand, Fine-Tuning offers unparalleled control and efficiency.
In the end, the decision to use RAG, Fine-Tuning, or a hybrid approach lies in understanding the problem at hand, the importance of scalability, and the need for real-time adaptability versus embedded, specialized knowledge. By deploying these techniques, businesses and developers can unlock the full potential of LLMs, creating solutions that are not only intelligent and efficient but also directed to user needs.
References
- Ezra, O. (2024, November 18). Retrieval-augmented generation VS fine-tuning: What’s right for you? Delivering Data Products in a Data Fabric & Data Mesh. https://www.k2view.com/blog/retrieval-augmented-generation-vs-fine-tuning/#What-is-Retrieval-Augmented-Generation
- MacDonald, L. (2024, August 1). Rag vs fine tuning: How to choose the right method. Monte Carlo Data. https://www.montecarlodata.com/blog-rag-vs-fine-tuning/
- Ghosh, B. (2024, February 25). When to apply rag vs fine-tuning. Medium. https://medium.com/@bijit211987/when-to-apply-rag-vs-fine-tuning-90a34e7d6d25
- Clyburn, C. (2024, September 9). RAG vs. Fine Tuning. YouTube. https://www.youtube.com/watch?v=00Q0G84kq3M