
Blog Posts
This blog page is designed to share knowledge on topics of interest, document valuable insights, and stay aligned with the latest trends. It serves as a platform for exploring ideas, refining writing skills, and connecting with like-minded individuals through original content.
Click on the tabs to explore the articles available on this page:
Prompt Engineering: Key Techniques for Better AI Responses
Written by Angelo Consorte | Published on November 17, 2024

What Is Prompt Engineering?
Prompt engineering, in the context of AI, is the process of designing and refining instructions (inputs) to obtain the most accurate, relevant, and useful responses (outputs).
Prompt engineering is like giving directions to a driver. If you provide clear, specific instructions, you are more likely to reach your destination quickly and accurately. However, if the directions are vague or unclear, the driver might get lost or take longer than needed. Similarly, well-crafted prompts guide AI to produce precise, useful responses, while poorly structured ones can lead to confusion or irrelevant results.
Why Is Prompt Engineering Relevant?
To understand the importance of prompt engineering, we first need to grasp how Large Language Models (LLMs) work. LLMs are trained using vast amounts of data from the internet. In simple terms, they work by predicting the next token (a unit of text, which could be a word or part of a word; for example, “chatbot” could be split into tokens: “chat” and “bot”). After being fine-tuned, they can respond to instructions, acting like an assistant to users.
For every prompt, the model selects from various tokens to generate a response. These variables are known as parameters, and typically, the model chooses the most probable next token based on the data it was trained on. These variables also measure the size of LLMs. For example, ChatGPT-4 has an estimated 1 trillion parameters, Llama 3.1 has 405 billion parameters, and Gemini 1.5 Pro is estimated also to have around 1 trillion parameters.
We are talking about vast amounts of data!
Additionally, LLMs are not search engines like Google or Bing, which match keywords in user queries to content online. They are reasoning engines because they can learn, think, and express their knowledge. Therefore, crafting clear prompts using the right techniques can significantly enhance the utility of these models for everyday tasks.
Best Practices
After discussing the relevance of prompt engineering, let’s dive into deploying LLMs using the best practices and techniques. Here is a list of the best practices to craft a good prompt:
1. Clarity and Context
- Grammar: The foundation of clarity is proper grammar and spelling. Poor grammar or misspelled words can lead to confusion, misinterpretation, or entirely different responses.
- Straightforwardness: Keep your prompt to the point. Avoid unnecessary filler words or complex sentence structures that may obscure your main request. For example, instead of saying, “Can you, like, tell me what happened during the event that occurred last week?”, you could simply say, “What happened during the event last week?”
- Context: A good prompt does not just ask for an answer, it provides the context needed to generate a meaningful response. For instance, if you’re asking an AI to help you write a social media post, you could say, “Write a Facebook post for a local coffee shop’s new seasonal drink, targeting young adults aged 18-25, highlighting the drink’s unique flavors and offering a limited-time discount.” The clearer and more detailed the context, the more relevant and useful the response will be.
- Specificity: The more specific you can be with your prompt, the better. Vague or general prompts can lead to responses that require a lot of back-and-forth to fine-tune. Specificity eliminates ambiguity.
2. Iterate and Refine
- Refining: The more complex the task, the more complex the prompt. Coming up with a new prompt for a complex task may result in a response that is not particularly useful. Refining and iterating are therefore very helpful practices.
- Implement Feedback: Your initial prompt doesn’t need to be perfect, but it should be a solid starting point. After receiving a response, carefully assess its quality. Does it answer the question fully? Is the information relevant? Based on feedback from the initial response, refine your prompt to be more specific.
- Expand Output: Finally, iteration can be used to fine-tune the outputs. After receiving a response, you might ask the AI to clarify certain points, expand on ideas, or rewrite sections in a different style.
3. Steps and Time
- Providing Steps: Providing clear steps can be helpful for two reasons: it gives the LLM a reliable guideline to follow, and it allows the model more time to process information without rushing to a conclusion.
- Time to Think: Instructing the model to take its time to come to a solution is a good practice, especially for more complex instructions, as it explicitly allows the model to go through a longer thought process.
4. Prompt Delimiters
- Signs and Symbols: Using prompt delimiters is another technique that helps us communicate with the model. By using symbols like “”, <>, \/, ||, we can indicate to the model which part of the text we are referring to.
- Communication: Many script formats use delimiters to communicate with machines. Even though LLMs easily understand natural language, using delimiters can still be helpful.
5. One- and Few-shot Learning
- One-shot learning: Involves providing a single example along with your prompt. This helps the AI understand the format or approach you expect for the response.
- Prompt: “Example: ‘Comfortable, high-quality backpack made with durable materials.’ Now, write a product description for running shoes.”
- AI output: “These running shoes offer comfort and speed, featuring lightweight material and excellent support.”
- Few-shot learning: Similar to one-shot learning, but with several examples—usually 2 to 5—so the AI can recognize patterns or the style you want in the output.
- Prompt: “Here are some examples of catchy social media captions: ‘Chase your dreams, not just your coffee.’ ‘Sundays are for relaxation and good vibes.’ Now, create a caption for a fitness brand.”
- AI Output: “Push yourself to new limits—your future self will thank you!”
6. Negative Prompting
- Negative Prompts: Involve explicitly telling the AI what to avoid in its response. By specifying what you don’t want, you can guide the AI to steer clear of certain types of content, tone, or style.
- Prompt: “Write a blog post about the benefits of exercise. Avoid mentioning weight loss or dieting.”
- AI output: “Exercise boosts energy, improves heart health, and enhances mental well-being.”
Conclusion
In conclusion, prompt engineering is a crucial skill when working with AI models, as it directly impacts the quality and relevance of the responses generated through simple practices and techniques.
By focusing on clarity, specificity, and iteration, you can significantly improve the effectiveness of your prompts, whether you’re crafting content, solving problems, or brainstorming ideas.
Furthermore, understanding each model specifically and considering ethical considerations ensures that AI-generated outputs are both accurate and responsible. As LLMs continue to improve, prompt engineering skills will help you leverage LLMs more effectively and ethically.
References
Open AI. (n.d.). What are tokens and how to count them? | openai help center. Open AI Help Center. https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
McKinsey & Company. (2024, March 22). What is prompt engineering?. McKinsey & Company. https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-prompt-engineering
Illustrating reinforcement learning from human feedback (RLHF). Hugging Face – The AI community building the future. (2022, December 9). https://huggingface.co/blog/rlhf#rlhf-lets-take-it-step-by-step
NG, A (2024, November 15) ChatGPT Prompt Engineering for Developers (Video of a course). DeepLearning.AI. https://learn.deeplearning.ai/courses/chatgpt-prompt-eng/lesson/2/guidelines
Unlocking the Power of LLMs: RAG and Fine-Tuning Techniques
Written by Angelo Consorte | Published on November 24, 2024
Retrieval-Augmented Generation (RAG) and Fine Tuning are two distinct techniques used in machine learning to enhance the performance of large language models (LLMs). Each of these techniques has its pros and cons and, in this text, we are going to discuss what exactly they are, how they can be useful, why we use them, and what cases to use them.

LLM Difficulties
The development of Large Language Models with user friendly interfaces is a movement that has changed the world. Available for everybody for free, LLMs like Chat GPT, Google Gemini, and Llama are incredible tools for innumerous tasks that help us by empowering individuals and businesses to achieve more with less effort. These tools provide unprecedented access to advanced AI capabilities, allowing users to draft essays, generate creative ideas, analyze data, translate languages, and even write code, all from a simple and intuitive interface. Their accessibility has democratized technology, breaking down barriers to entry for complex tasks that previously required specialized skills or resources.
Even considering all its capabilities, models have their limitations that can restrict how helpful they can be. One of their limitations is that sometimes, to answer questions accurately, LLMs have to be trained on that specific data. Imagine a scenario where someone asks the LLM:
“What are the opening hours of the new café, Sunshine Roastery, that opened in downtown Springfield last month?”
If the LLM was trained on a dataset that predates the café’s opening or lacks detailed information about small, local businesses, it might not have any data on the café.
LLMs rely on pre-existing datasets for their knowledge. Unless the model is updated or augmented with external web-based queries, it cannot provide accurate or current details about events or entities that appeared after its training period or fall outside the scope of its dataset.
Another limitation of LLMs is their inherently generalistic nature, which can make them less effective for highly specific or specialized tasks. While they excel at providing broad, context-aware responses, they often lack the precision or depth required for niche applications. For example, a business in the pharmaceutical industry might need detailed insights into drug interactions or compliance regulations specific to a particular country. An LLM trained in general knowledge might provide surface-level information or outdated guidelines, which could be insufficient or even misleading.
This is when techniques like Fine Tuning and Retrieval Augmented Generation come into play. On their particular ways, these techniques help us enhance the use of LLMs for our needs. In the next paragraphs we are going to define each technique and discuss what are the best uses for them.
Retrieval Augmented Generation (RAG)
What is RAG?
RAG, or Retrieval-Augmented Generation, is an architecture framework introduced by Meta in 2020 that combines a language model with an external retrieval mechanism.
Unlike traditional LLMs that rely exclusively on pre-trained knowledge, RAG dynamically pulls relevant information from a connected knowledge base, database, or document repository to generate responses. This means that the output is not just based on what the model has learned during training but is also influenced by the most pertinent data retrieved in real time. This makes RAG particularly powerful for applications requiring precise, contextually rich, and up-to-date answers.
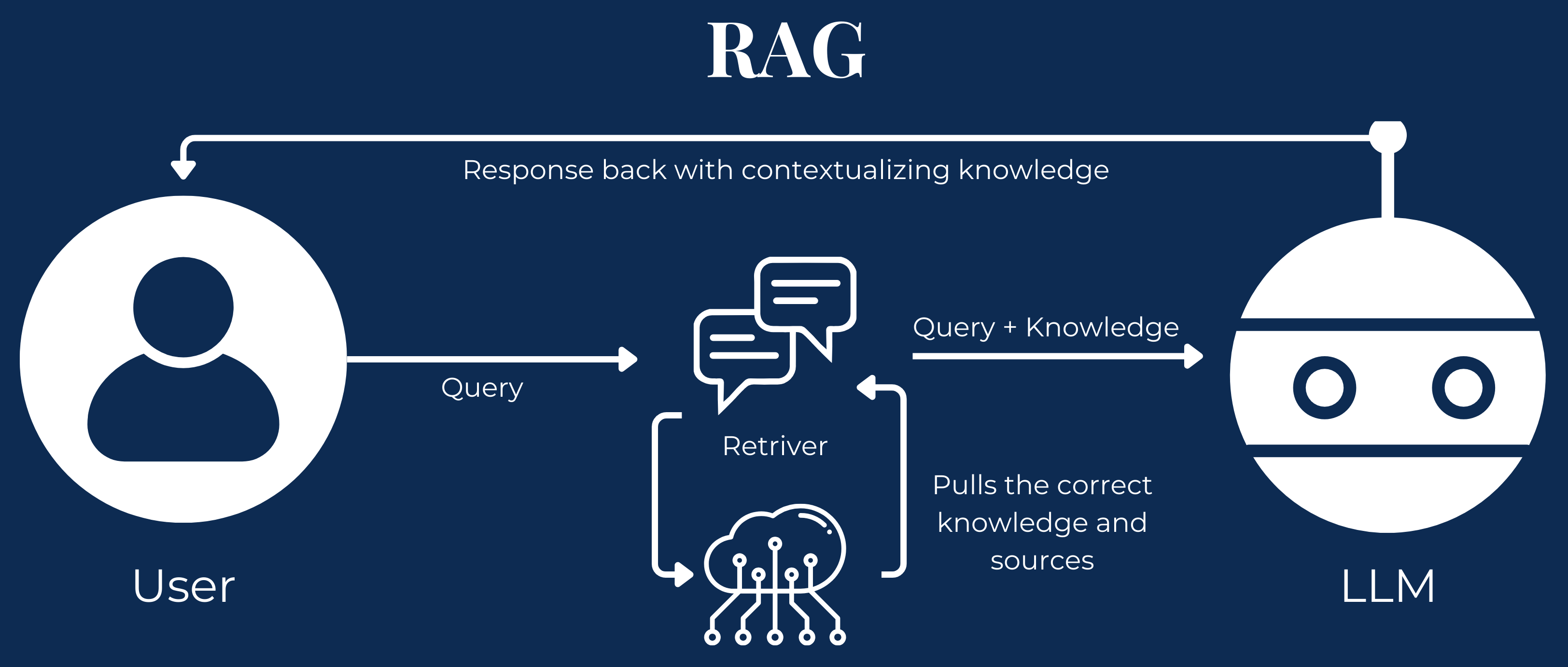
How does our interactions with LLMs that use RAG work?
- Query processing: The process starts when a user inputs a query into the system, initiating the retrieval mechanism of the RAG chain.
- Data retrieval: The RAG system then searches the database for relevant information based on the query, utilizing advanced algorithms to match the query with the most suitable and contextually appropriate data.
- Integration with the LLM: The retrieved data is combined with the user’s original query and passed to the LLM.
- Response generation: Leveraging the LLM’s capabilities and the context from the retrieved data, the system produces a response that is accurate and tailored to the query’s specific context.
Pros of RAG
- Access to up-to-date information: RAG allows the model to retrieve real-time data, ensuring that responses are current and reflect the latest knowledge.
- Improved accuracy: By incorporating external, curated databases, RAG can provide more precise and reliable answers than a model relying solely on its internal training data.
- Increased flexibility: It can be applied to various domains, as it can pull information from different databases or sources tailored to the specific task.
- Cost-effective: RAG is cheaper than fine-tuning, as it does not require retraining the entire model and instead relies on retrieving external information to improve performance.
Cons of RAG
- Dependency on external data sources: RAG’s performance is tied to the quality and reliability of external databases or retrieval systems. If the sources are outdated, inaccurate, or incomplete, the generated responses may suffer.
- Increased computational overhead: Retrieving relevant information from external sources adds extra processing time and computational resources, which can affect response time and scalability.
Fine Tuning
What is Fine Tuning?
Fine-tuning, a technique in machine learning where a pre-trained model is further trained on a new, specific dataset, has been utilized since the early 1990s. This approach gained prominence with the advent of deep learning, particularly in natural language processing (NLP) and computer vision tasks.
Instead of training a model from scratch, fine-tuning leverages the existing knowledge embedded in a pre-trained model and refines it with additional data. This approach, which became widely adopted with the advent of models like BERT and GPT, allows developers to optimize a model’s performance for specific use cases while significantly reducing the time, computational resources, and data requirements compared to training from the ground up.
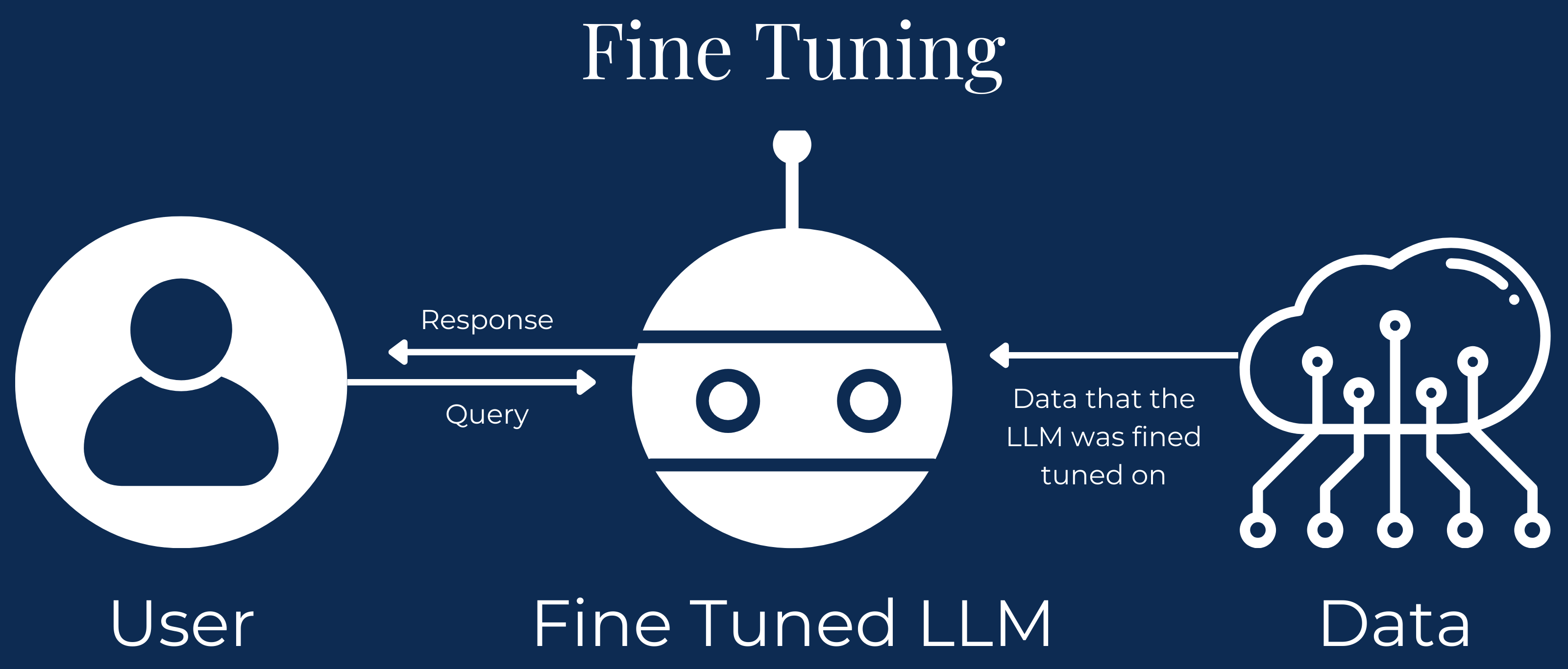
How does our interactions with LLMs that use Fine Tuning work?
- Preprocessing: The interaction begins when a user submits an input. The input is then processed to ensure it aligns with the format and structure expected by the fine-tuned model, such as tokenization for text inputs or normalization for images.
- Inference with the fine-tuned model: The preprocessed input is passed to the fine-tuned model, which applies its domain-specific adjustments and learned patterns to generate a response or prediction.
- Postprocessing: The model’s output is refined, if necessary, to meet the user’s desired format or additional constraints, such as converting probabilities into a class label or generating user-friendly text.
Pros of Fine Tuning
- Faster Responses Compared to RAG: Fine-tuned models embed all relevant knowledge into their weights, eliminating the need for external retrieval processes, resulting in faster and more efficient response generation.
- Understanding of the Domain: Fine-tuning trains the model to grasp overarching domain concepts, enabling it to generalize across related tasks rather than relying solely on isolated dataset-specific knowledge.
- Style and Tone: Fine-tuning allows the model to be adapted to a specific tone, style, or level of formality, making it ideal for tailored communications, creative writing, or brand-aligned outputs.
- Offline Functionality: Fine-tuned models do not rely on external data sources or internet connectivity, making them more secure and practical for offline environments.
Cons of Fine Tuning
- Higher Costs Compared to RAG: Fine-tuning requires significant computational resources, time, and expertise, which can make it more expensive than RAG, especially for large-scale models.
- Challenging to Update Knowledge: Updating a fine-tuned model with new information requires retraining or re-fine-tuning, making it time-intensive and impractical for rapidly changing domains.
- Risk of Overfitting on Small or Specialized Datasets: Fine-tuning on limited or narrow datasets can lead to overfitting, where the model performs well on training data but poorly on new, unseen data.
- Limited Scalability Across Multiple Domains: Scaling fine-tuned models for diverse domains require separate fine-tuning for each, which can quickly become resource prohibitive.
Use Cases of RAG
Dynamic Databases
- RAG works well when you need to continuously pull information from dynamic, updated data sources like databases, APIs, or document repositories.
- Real-World Example: a helpdesk assistant fetching up-to-date FAQs, troubleshooting guides, or policy documents directly from a company’s knowledge base to answer customer queries. This ensures that the responses are current and relevant without requiring model retraining.
Systems that Require Sources:
- RAG supports the retrieval of external data with citations, making it easier to provide transparent and verifiable responses.
- Real-World Example: a Legal Research Tool that retrieves case law, statutes, or legal precedents along with their sources, providing lawyers with not just the information but its origin for further review.
Reducing Hallucinations
- By fetching information directly from reliable sources, RAG minimizes hallucinations, improving trust in its outputs.
- Real-World Example: a Medical Diagnosis Assistant for clinicians that retrieves recent studies, drug information, or treatment guidelines from medical databases like PubMed, ensuring that responses are based on verifiable sources.
Maintenance
- The external data source can be curated and updated without retraining the model. This makes it easier to manage evolving knowledge and ensure accuracy.
- Real-World Example: an E-Commerce Assistant chatbot that retrieves product availability, pricing, and reviews directly from a store’s inventory system, ensuring responses reflect the latest updates.
Use Cases of Fine Tuning
Influence on Model Behaviors and Reactions
- Fine-tuning allows precise control over the model’s behavior by training it on domain-specific data, aligning it closely with specific tasks, styles, or company branding.
- Real-World Example: a Customer Service Chatbot fine-tuned model for a financial institution that adheres to a formal tone, understands nuanced financial jargon, and provides tailored responses for banking products.
Speed, Inference Cost, and Offline Capabilities
- Once fine-tuned, the model is standalone and can operate offline, providing faster responses with lower inference costs compared to using a retrieval mechanism.
- Real-World Example: a fine-tuned model deployed on an offline device, like a virtual assistant in a smart home system, ensuring low latency and no dependency on internet connectivity.
Cultural Sensitivity and Emotional Intelligence
- Fine-tuning allows models to adapt their tone, language, and behavior to align with cultural norms and emotional needs, creating more personalized and respectful interactions.
- Real-World Example: a global chatbot that adjusts its tone to match cultural expectations (e.g., politeness in Japanese interactions) while also detecting user sentiment to provide empathetic and emotionally aware responses.
Combining Both Techniques
Finally, it is also possible to combine both techniques in order to build even more complex applications. By putting both tactics together, we can take advantage of the characteristics of both and provide better outputs for users.
- Personalized educational tutor: an application designed to assist students across various subjects and skill levels.
- RAG components: The application dynamically retrieves the latest curriculum updates, reference materials, or specific answers from trusted educational repositories like academic journals, textbooks, or online resources, ensuring that the information provided is accurate, up-to-date, and sourced.
- Fine-Tuning Component: The model is fine-tuned to understand the emotional and motivational needs of learners, adapting its tone and instructional style to the user’s preferences. For instance, it could provide encouraging feedback for a struggling student or challenge an advanced learner with more complex problems.
This dual approach creates a tutor that is not only reliable in its information but also engaging, empathetic, and effective in fostering personalized learning experiences.
Consclusion
In conclusion, Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful yet distinct approaches to optimizing Large Language Models (LLMs), each directed to specific uses and challenges. RAG is better in dynamic, real-time scenarios requiring access to up-to-date, contextual information, while Fine-Tuning excels in creating domain-specific, stylistically consistent, and offline-ready models.
Choosing between these techniques—or combining them—depends on your goals and constraints. RAG’s real-time retrieval capability ensures flexibility and accuracy for constantly evolving knowledge bases, on the other hand, Fine-Tuning offers unparalleled control and efficiency.
In the end, the decision to use RAG, Fine-Tuning, or a hybrid approach lies in understanding the problem at hand, the importance of scalability, and the need for real-time adaptability versus embedded, specialized knowledge. By deploying these techniques, businesses and developers can unlock the full potential of LLMs, creating solutions that are not only intelligent and efficient but also directed to user needs.
Sources
Ezra, O. (2024, November 18). Retrieval-augmented generation VS fine-tuning: What’s right for you? Delivering Data Products in a Data Fabric & Data Mesh. https://www.k2view.com/blog/retrieval-augmented-generation-vs-fine-tuning/#What-is-Retrieval-Augmented-Generation
MacDonald, L. (2024, August 1). Rag vs fine tuning: How to choose the right method. Monte Carlo Data. https://www.montecarlodata.com/blog-rag-vs-fine-tuning/
Ghosh, B. (2024, February 25). When to apply rag vs fine-tuning. Medium. https://medium.com/@bijit211987/when-to-apply-rag-vs-fine-tuning-90a34e7d6d25
Clyburn, C. (2024, September 9). RAG vs. Fine Tuning. YouTube. https://www.youtube.com/watch?v=00Q0G84kq3M
AI Development: From Early Concepts to Modern Generative Tools
Written by Angelo Consorte | Published on November 28, 2024

Introduction
Artificial Intelligence (AI) has become increasingly important, particularly in recent years. It is almost unimaginable not to hear or read the term “Artificial Intelligence” at least once within a week.
In late October and early November 2024, Apple began introducing its proprietary AI applications, branded as Apple Intelligence, across its devices.
Furthermore, in October of this year, OpenAI secured an unprecedented $6.6 billion in funding, which is expected to drive extensive research and development efforts, expand computational capabilities, and further its mission to advance the field of artificial intelligence.
According to a report by Bloomberg, the generative AI sector alone is projected to evolve into a $1.3 trillion market by 2032.
These developments suggest we are at the threshold of a transformative era, one with the potential to shape our future profoundly. But what exactly is AI? Why is this technology becoming so prevalent in our daily lives? What are its applications, and in what contexts does it find relevance?
History of AI
In the early 20th century, science fiction introduced the concept of artificial intelligence through iconic characters like the Tin Man from The Wizard of Oz. By the 1950s, this cultural groundwork had profoundly influenced a generation of scientists and mathematicians, embedding the concept of AI deeply into their intellectual and creative pursuits.
Alan Turing, a British polymath, was one of many from this generation who began exploring the mathematical foundations of artificial intelligence. In his 1950 paper Computing Machinery and Intelligence, he proposed that machines could solve problems and make decisions using information and reasoning, much like humans. However, Turing’s progress was limited by early computers’ inability to store commands and prohibitively high costs, which required proof of concept and influential support to advance research.
In 1956, the “Logic Theorist” became the first AI program ever developed. Created by Allen Newell, Cliff Shaw, and Herbert Simon, this work served as proof of Alan Turing’s early ideas on machine intelligence. The program mimicked human problem-solving and was presented at the Dartmouth Summer Research Project on Artificial Intelligence, where John McCarthy coined the term “artificial intelligence.”
Over the next few decades, as computing technology became faster, cheaper, and more accessible, significant advancements occurred in AI. Machine learning algorithms improved, John Hopfield and David Rumelhart popularized deep learning techniques allowing computers to learn from experience, and Edward Feigenbaum introduced expert systems mimicking human decision-making processes. Gradually, the obstacles that had seemed insurmountable in AI’s early days became less significant. The fundamental limitation of computer storage, which held back progress 30 years earlier, was no longer an issue.
Now, in the era of big data, vast amounts of information exceed human processing capacity. AI has proven valuable across numerous industries, leveraging massive datasets and computational power to learn efficiently.
With sufficient computational and storage capacity, AI is now accessible to a broader audience, enabling everyone to benefit from decades of research and innovation.
Definition
Artificial intelligence is essentially technology that enables machines and computers to mimic human behaviors like learning, solving problems, creating, and making decisions.
In everyday life, AI is everywhere. It helps unlock smartphones with facial recognition and corrects typing errors with autocorrect. Search engines like Google predict what you are looking for as you type, while social media apps like Instagram or TikTok display posts tailored to your interests.
- Facial recognition systems use computer vision and machine learning algorithms, often based on convolutional neural networks (CNNs), to analyze and compare facial features from an image or video to stored data.
- Autocorrect relies on natural language processing (NLP). It uses language models trained on large text datasets to predict and suggest the most likely word based on context and spelling patterns.
- Search engines use NLP, machine learning, and data mining to analyze previous search data, user behavior, and linguistic patterns. Algorithms like Google’s RankBrain evaluate context to provide real-time suggestions and refine results.
In 2024, most AI researchers and headlines are centered around advancements in generative AI—a technology capable of producing original text, images, and videos. To understand generative AI, it’s essential to grasp the foundational technologies on which it relies.
AI can be understood as a hierarchy of concepts:
- Artificial intelligence (machines that mimic human intelligence)
- Machine learning (AI systems that learn from historical data)
- Deep learning (ML models that mimic human brain functions)
- Generative AI (deep learning models that create original content)
- Deep learning (ML models that mimic human brain functions)
- Machine learning (AI systems that learn from historical data)
The evolution of these concepts is why we can now leverage advanced tools to enhance productivity in various areas of life.
AI tools like ChatGPT have brought this technology into the public spotlight, prompting questions about what makes today’s AI advancements different and what the future holds. The field has experienced cycles of progress and skepticism, known as the “seasons of AI.” However, this “AI summer” marks a new phase of sustained impact, rather than inflated expectations.
Currently, much of AI’s focus is on productivity. According to PricewaterhouseCoopers, the boost in productivity enabled by AI could add $6.6 trillion to the global economy by 2030.
AI has become integral to daily life, enhancing productivity and transforming industries with its ability to mimic human intelligence. From foundational technologies like machine learning and deep learning to advancements in generative AI, its evolution continues to shape the future. However, as AI grows, so does the hype, often blurring the line between true innovation and exaggeration—an issue worth exploring further.
AI in Context
The potential of AI is vast and exciting, yet the term “artificial intelligence” is often used loosely to encompass a wide range of technologies and approaches that mimic aspects of human intelligence. This broadness has made AI a prime target for marketing and hype, with companies frequently labeling systems as “AI” to attract attention, even when these systems lack genuine learning capabilities or advanced intelligence.
For instance, a simple chatbot that relies on basic keyword matching may be labeled as “AI” simply because it mimics conversational behavior, even though it lacks the characteristics of more complex AI models, such as learning from interactions or understanding context. This kind of misrepresentation fosters unrealistic expectations among users and undermines the credibility of AI as a transformative technology.
When tools are marketed as AI without possessing advanced capabilities, it becomes harder for consumers and businesses to discern genuine innovation from superficial features. This confusion can lead to misplaced investments, skepticism about AI’s potential, and missed opportunities to adopt tools that could truly enhance productivity and problem-solving.
Conclusion
Artificial intelligence has firmly established itself as a transformative force in modern society, driving innovation on different industries and reshaping the way we interact with technology. From its historical origins and foundational advancements to the latest breakthroughs in generative AI, the journey of AI reflects the pursuit of mimicking human intelligence to enhance efficiency, creativity, and decision-making.
However, with great potential comes the need for discernment. The continuous growth of AI, requires us to understand how to distinguish genuine advancements from overhyped claims. As we stand on the cusp of an AI-driven future, informed understanding and ethical innovation will be key to harnessing its true power while ensuring its benefits are accessible and meaningful for all.
Sources
Bean, R. (2017, May 8). How big data is empowering AI and machine learning at scale. MIT Sloan Management Review. https://sloanreview.mit.edu/article/how-big-data-is-empowering-ai-and-machine-learning-at-scale/
Smith, R. (2024, February 8). The Ai Explosion, explained. Duke Today. https://today.duke.edu/2024/02/ai-explosion-explained
Bloomberg. (2023, June 1). Generative AI to become a $1.3 trillion market by 2032, research finds | press | Bloomberg LP. Bloomberg.com. https://www.bloomberg.com/company/press/generative-ai-to-become-a-1-3-trillion-market-by-2032-research-finds/
- Stryker, C., & Eda Kavlakoglu, E. (2024, October 25). What is Artificial Intelligence (AI)?. IBM. https://www.ibm.com/topics/artificial-intelligence
Johnson, A. (2024, October 28). Apple Intelligence is out. The Verge. https://www.theverge.com/2024/10/28/24272995/apple-intelligence-now-available-ios-18-1-mac-ipad
IV, A. P. (2024, October 4). OpenAI valued at $157 billion after closing $6.6 billion funding round. Forbes. https://www.forbes.com/sites/antoniopequenoiv/2024/10/02/openai-valued-at-157-billion-after-closing-66-billion-funding-round/
Anyoha, R. (2020, April 23). The history of Artificial Intelligence. Science in the News. https://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/
TURING, A. M. (1950). I.—Computing Machinery and intelligence. Mind, LIX(236), 433–460. https://doi.org/10.1093/mind/lix.236.433